4. Ensembles
4.1. Ensemble reduction
This tutorial will explore ensemble reduction (also known as ensemble selection) using xscen. This will use pre-computed annual mean temperatures from xclim.testing.
[2]:
import pooch
import xarray as xr
from xclim.testing.utils import nimbus
import xscen as xs
downloader = pooch.HTTPDownloader(headers={"User-Agent": f"xscen-{xs.__version__}"})
datasets = {
"ACCESS": "EnsembleStats/BCCAQv2+ANUSPLIN300_ACCESS1-0_historical+rcp45_r1i1p1_1950-2100_tg_mean_YS.nc",
"BNU-ESM": "EnsembleStats/BCCAQv2+ANUSPLIN300_BNU-ESM_historical+rcp45_r1i1p1_1950-2100_tg_mean_YS.nc",
"CCSM4-r1": "EnsembleStats/BCCAQv2+ANUSPLIN300_CCSM4_historical+rcp45_r1i1p1_1950-2100_tg_mean_YS.nc",
"CCSM4-r2": "EnsembleStats/BCCAQv2+ANUSPLIN300_CCSM4_historical+rcp45_r2i1p1_1950-2100_tg_mean_YS.nc",
"CNRM-CM5": "EnsembleStats/BCCAQv2+ANUSPLIN300_CNRM-CM5_historical+rcp45_r1i1p1_1970-2050_tg_mean_YS.nc",
}
for d in datasets:
file = nimbus().fetch(datasets[d], downloader=downloader)
ds = xr.open_dataset(file).isel(lon=slice(0, 4), lat=slice(0, 4))
ds = xs.climatological_op(
ds,
op="mean",
window=30,
periods=[[1981, 2010], [2021, 2050]],
horizons_as_dim=True,
).drop_vars("time")
datasets[d] = xs.compute_deltas(ds, reference_horizon="1981-2010")
Downloading file 'EnsembleStats/BCCAQv2+ANUSPLIN300_ACCESS1-0_historical+rcp45_r1i1p1_1950-2100_tg_mean_YS.nc' from 'https://raw.githubusercontent.com/Ouranosinc/xclim-testdata/v2025.4.29/data/EnsembleStats/BCCAQv2+ANUSPLIN300_ACCESS1-0_historical+rcp45_r1i1p1_1950-2100_tg_mean_YS.nc' to '/home/docs/.cache/xclim-testdata/v2025.4.29'.
Downloading file 'EnsembleStats/BCCAQv2+ANUSPLIN300_BNU-ESM_historical+rcp45_r1i1p1_1950-2100_tg_mean_YS.nc' from 'https://raw.githubusercontent.com/Ouranosinc/xclim-testdata/v2025.4.29/data/EnsembleStats/BCCAQv2+ANUSPLIN300_BNU-ESM_historical+rcp45_r1i1p1_1950-2100_tg_mean_YS.nc' to '/home/docs/.cache/xclim-testdata/v2025.4.29'.
Downloading file 'EnsembleStats/BCCAQv2+ANUSPLIN300_CCSM4_historical+rcp45_r1i1p1_1950-2100_tg_mean_YS.nc' from 'https://raw.githubusercontent.com/Ouranosinc/xclim-testdata/v2025.4.29/data/EnsembleStats/BCCAQv2+ANUSPLIN300_CCSM4_historical+rcp45_r1i1p1_1950-2100_tg_mean_YS.nc' to '/home/docs/.cache/xclim-testdata/v2025.4.29'.
Downloading file 'EnsembleStats/BCCAQv2+ANUSPLIN300_CCSM4_historical+rcp45_r2i1p1_1950-2100_tg_mean_YS.nc' from 'https://raw.githubusercontent.com/Ouranosinc/xclim-testdata/v2025.4.29/data/EnsembleStats/BCCAQv2+ANUSPLIN300_CCSM4_historical+rcp45_r2i1p1_1950-2100_tg_mean_YS.nc' to '/home/docs/.cache/xclim-testdata/v2025.4.29'.
Downloading file 'EnsembleStats/BCCAQv2+ANUSPLIN300_CNRM-CM5_historical+rcp45_r1i1p1_1970-2050_tg_mean_YS.nc' from 'https://raw.githubusercontent.com/Ouranosinc/xclim-testdata/v2025.4.29/data/EnsembleStats/BCCAQv2+ANUSPLIN300_CNRM-CM5_historical+rcp45_r1i1p1_1970-2050_tg_mean_YS.nc' to '/home/docs/.cache/xclim-testdata/v2025.4.29'.
[3]:
datasets
[3]:
{'ACCESS': <xarray.Dataset> Size: 264B
Dimensions: (lon: 4, lat: 4, horizon: 2)
Coordinates:
* lon (lon) float64 32B -74.96 ... -74.71
* lat (lat) float64 32B 45.04 45.12 45.21 45.29
* horizon (horizon) <U9 72B '1981-2010' '2021-2050'
Data variables:
tg_mean_clim_mean_delta_1981_2010 (horizon, lat, lon) float32 128B 0.0 ....
Attributes: (12/36)
institution: Canadian Centre for Climate Services (CCCS)
contact: Canadian Centre for Climate Services
Conventions: CF-1.4
institute_id: CCCS
domain: Canada
creation_date: 2017-10-24T11:58:08PDT
... ...
title: Bias Correction/Constructed Analogue Quan...
history:
climateindex_package_id: https: // github.com / Ouranosinc / xclim
downscaling_institution: Pacific Climate Impacts Consortium (PCIC)...
downscaling_institute_id: PCIC
cat:processing_level: deltas,
'BNU-ESM': <xarray.Dataset> Size: 264B
Dimensions: (lon: 4, lat: 4, horizon: 2)
Coordinates:
* lon (lon) float64 32B -74.96 ... -74.71
* lat (lat) float64 32B 45.04 45.12 45.21 45.29
* horizon (horizon) <U9 72B '1981-2010' '2021-2050'
Data variables:
tg_mean_clim_mean_delta_1981_2010 (horizon, lat, lon) float32 128B 0.0 ....
Attributes: (12/36)
institution: Canadian Centre for Climate Services (CCCS)
contact: Canadian Centre for Climate Services
Conventions: CF-1.4
institute_id: CCCS
domain: Canada
creation_date: 2017-11-02T12:54:16PDT
... ...
title: Bias Correction/Constructed Analogue Quan...
history:
climateindex_package_id: https: // github.com / Ouranosinc / xclim
downscaling_institution: Pacific Climate Impacts Consortium (PCIC)...
downscaling_institute_id: PCIC
cat:processing_level: deltas,
'CCSM4-r1': <xarray.Dataset> Size: 264B
Dimensions: (lon: 4, lat: 4, horizon: 2)
Coordinates:
* lon (lon) float64 32B -74.96 ... -74.71
* lat (lat) float64 32B 45.04 45.12 45.21 45.29
* horizon (horizon) <U9 72B '1981-2010' '2021-2050'
Data variables:
tg_mean_clim_mean_delta_1981_2010 (horizon, lat, lon) float32 128B 0.0 ....
Attributes: (12/36)
institution: Canadian Centre for Climate Services (CCCS)
contact: Canadian Centre for Climate Services
Conventions: CF-1.4
institute_id: CCCS
domain: Canada
creation_date: 2017-08-01T19:54:05PDT
... ...
title: Bias Correction/Constructed Analogue Quan...
history:
climateindex_package_id: https: // github.com / Ouranosinc / xclim
downscaling_institution: Pacific Climate Impacts Consortium (PCIC)...
downscaling_institute_id: PCIC
cat:processing_level: deltas,
'CCSM4-r2': <xarray.Dataset> Size: 264B
Dimensions: (lon: 4, lat: 4, horizon: 2)
Coordinates:
* lon (lon) float64 32B -74.96 ... -74.71
* lat (lat) float64 32B 45.04 45.12 45.21 45.29
* horizon (horizon) <U9 72B '1981-2010' '2021-2050'
Data variables:
tg_mean_clim_mean_delta_1981_2010 (horizon, lat, lon) float32 128B 0.0 ....
Attributes: (12/36)
institution: Canadian Centre for Climate Services (CCCS)
contact: Canadian Centre for Climate Services
Conventions: CF-1.4
institute_id: CCCS
domain: Canada
creation_date: 2017-12-05T02:07:22PST
... ...
title: Bias Correction/Constructed Analogue Quan...
history:
climateindex_package_id: https: // github.com / Ouranosinc / xclim
downscaling_institution: Pacific Climate Impacts Consortium (PCIC)...
downscaling_institute_id: PCIC
cat:processing_level: deltas,
'CNRM-CM5': <xarray.Dataset> Size: 264B
Dimensions: (lon: 4, lat: 4, horizon: 2)
Coordinates:
* lon (lon) float64 32B -74.96 ... -74.71
* lat (lat) float64 32B 45.04 45.12 45.21 45.29
* horizon (horizon) <U9 72B '1981-2010' '2021-2050'
Data variables:
tg_mean_clim_mean_delta_1981_2010 (horizon, lat, lon) float32 128B 0.0 ....
Attributes: (12/37)
institution: Canadian Centre for Climate Services (CCCS)
contact: Canadian Centre for Climate Services
Conventions: CF-1.4
institute_id: CCCS
domain: Canada
creation_date: 2017-05-19T13:54:07PDT
... ...
project_id: CMIP5
NCO: "4.6.0"
climateindex_package_id: https: // github.com / Ouranosinc / xclim
downscaling_institution: Pacific Climate Impacts Consortium (PCIC)...
downscaling_institute_id: PCIC
cat:processing_level: deltas}
4.1.1. Preparing the data
Ensemble reduction is built upon climate indicators that are relevant to represent the ensemble’s variability for a given application. In this case, we’ll use the mean temperature delta between 2021-2050 and 1981-2010, but monthly or seasonal indicators could also be required. The horizons_as_dim argument in climatological_op can help combine indicators of multiple frequencies into a single dataset. Alternatively, xscen.utils.unstack_dates can also accomplish the same thing if the
climatological operations have already been computed.
The functions implemented in xclim.ensembles._reduce require a very specific 2-D DataArray of dimensions “realization” and “criteria”. The first solution is to first create an ensemble using xclim.ensembles.create_ensemble, then pass the result to xclim.ensembles.make_criteria. Alternatively, the datasets can be passed directly to xscen.ensembles.reduce_ensemble and the necessary preliminary steps will be accomplished automatically.
In this example, the number of criteria will corresponds to: indicators x horizons x longitude x latitude, but criteria that are purely NaN across all realizations will be removed.
Note that xs.spatial_mean could have been used prior to calling that function to remove the spatial dimensions.
4.1.2. Selecting a reduced ensemble
NOTE
Ensemble reduction in xscen is built upon xclim.ensembles. For more information on basic usage and available methods, please consult their documentation.
Ensemble reduction through xscen.reduce_ensemble consists in a simple call to xclim. The arguments are:
data, which is the aforementioned 2D DataArray, or the list/dict of datasets required to build it.methodis eitherkkzorkmeans. See the link above for further details on each technique.horizonsis used to instruct on which horizon(s) to build the data from, if data needs to be constructed.create_kwargs, the arguments to pass toxclim.ensembles.create_ensembleif data needs to be constructed.kwargsis a dictionary of arguments to send to the clustering method chosen.
[4]:
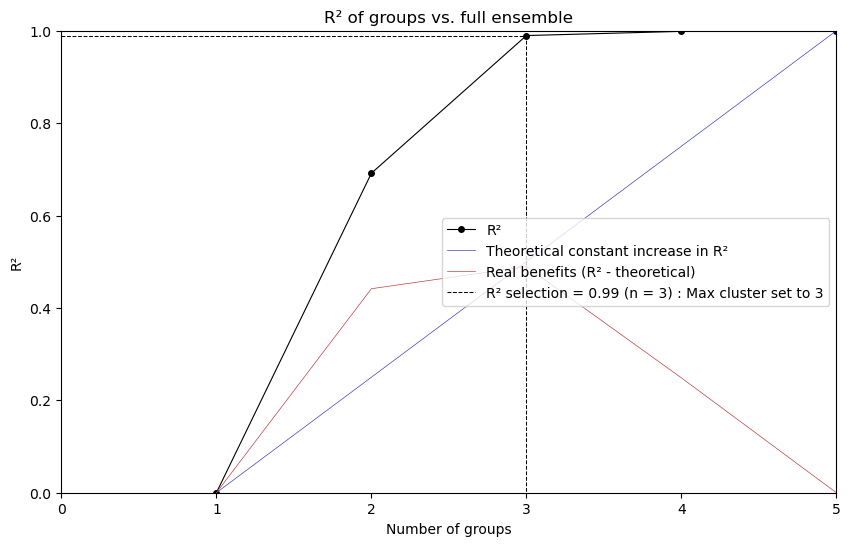
selected, clusters, fig_data = xs.reduce_ensemble(
data=datasets, method="kmeans", horizons=["2021-2050"], max_clusters=3
)
The method always returns 3 outputs (selected, clusters, fig_data):
selectedis a DataArray of dimension ‘realization’ listing the selected simulations.clusters(kmeans only) groups every realization in their respective clusters in a python dictionary.fig_data(kmeans only) can be used to callxclim.ensembles.plot_rsqprofile(fig_data)
[5]:
selected
[5]:
<xarray.DataArray 'realization' (realization: 3)> Size: 96B
array(['ACCESS', 'BNU-ESM', 'CNRM-CM5'], dtype='<U8')
Coordinates:
* realization (realization) <U8 96B 'ACCESS' 'BNU-ESM' 'CNRM-CM5'
Attributes:
axis: E[6]:
# To see the clusters in more details
clusters
[6]:
{np.int32(0): <xarray.DataArray 'realization' (realization: 3)> Size: 96B
array(['ACCESS', 'CCSM4-r1', 'CCSM4-r2'], dtype='<U8')
Coordinates:
* realization (realization) <U8 96B 'ACCESS' 'CCSM4-r1' 'CCSM4-r2'
Attributes:
axis: E,
np.int32(1): <xarray.DataArray 'realization' (realization: 1)> Size: 32B
array(['CNRM-CM5'], dtype='<U8')
Coordinates:
* realization (realization) <U8 32B 'CNRM-CM5'
Attributes:
axis: E,
np.int32(2): <xarray.DataArray 'realization' (realization: 1)> Size: 32B
array(['BNU-ESM'], dtype='<U8')
Coordinates:
* realization (realization) <U8 32B 'BNU-ESM'
Attributes:
axis: E}
[7]:
from xclim.ensembles import plot_rsqprofile
plot_rsqprofile(fig_data)
4.2. Ensemble partition
This tutorial will show how to use xscen to create the input for xclim partition functions.
[8]:
# Get catalog
from pathlib import Path
import xclim as xc
output_folder = Path().absolute() / "_data"
cat = xs.DataCatalog(str(output_folder / "tutorial-catalog.json"))
# create a dictionary of datasets wanted for the partition
input_dict = cat.search(variable="tas", member="r1i1p1f1").to_dataset_dict(
xarray_open_kwargs={"engine": "h5netcdf"}
)
datasets = {}
for k, v in input_dict.items():
ds = xc.atmos.tg_mean(v.tas).to_dataset()
ds.attrs = v.attrs
datasets[k] = ds
--> The keys in the returned dictionary of datasets are constructed as follows:
'id.domain.processing_level.xrfreq'
From a dictionary of datasets, the function creates a dataset with new dimensions in partition_dim(["source", "experiment", "bias_adjust_project"], if they exist). In this toy example, we only have different experiments.
By default, it translates the xscen vocabulary (eg.
experiment) to the xclim partition vocabulary (eg.scenario). It is possible to passrename_dictto rename the dimensions with other names.If the inputs are not on the same grid, they can be regridded through
regrid_kwor subset to a point throughsubset_kw. The functions assumes that if there are differentbias_adjust_project, they will be on different grids (with allsourceon the same grid). If there is one or lessbias_adjust_project, the assumption is thatsourcehave different grids.You can also compute indicators on the data if the input is daily. This can be especially useful when the daily input data is on different calendars.
[9]:
# build a single dataset
import xclim as xc
ds = xs.ensembles.build_partition_data(
datasets,
subset_kw=dict(name="mtl", method="gridpoint", lat=[45.5], lon=[-73.6]),
)
ds
[9]:
<xarray.Dataset> Size: 120B
Dimensions: (time: 2, scenario: 4, model: 1)
Coordinates:
* time (time) datetime64[ns] 16B 2001-01-01 2002-01-01
* scenario (scenario) object 32B 'ssp126' 'ssp245' 'ssp370' 'ssp585'
* model (model) object 8B 'NCC_NorESM2-MM_r1i1p1f1'
Data variables:
tg_mean (model, scenario, time) float64 64B dask.array<chunksize=(1, 1, 2), meta=np.ndarray>
Attributes: (12/18)
comment: This is a test file created for the xscen tutorial...
cat:activity: ScenarioMIP
history: [2026-07-06 21:09:05] gridpoint spatial subsetting...
cat:source: NorESM2-MM
cat:processing_level: partition-ensemble
cat:institution: NCC
... ...
cat:domain: mtl
cat:member: r1i1p1f1
cat:mip_era: CMIP6
cat:date_end: 2002-12-31 00:00:00
version: v20191108
cat:id: CMIP6_ScenarioMIP_NCC_NorESM2-MM_r1i1p1f1_mtlPass the input to an xclim partition function.
[11]:
# compute uncertainty partitioning
mean, uncertainties = xc.ensembles.hawkins_sutton(ds.tg_mean)
uncertainties
[11]:
<xarray.DataArray 'getitem-fbdb46b6e6e73065ed9b85d66d996380' (uncertainty: 4,
time: 4)> Size: 128B
dask.array<concatenate, shape=(4, 4), dtype=float64, chunksize=(1, 2), chunktype=numpy.ndarray>
Coordinates:
* uncertainty (uncertainty) <U11 176B 'variability' 'model' ... 'total'
* time (time) object 32B 2001-01-01 00:00:00 ... 2004-01-01 00:00:00
Attributes:
model: ['NCC_NorESM2-MM_r1i1p1f1']
scenario: ['ssp126' 'ssp245' 'ssp370' 'ssp585']NOTE
Note that the figanos library provides a function fg.partition to plot the uncertainties.