[2]:
from pathlib import Path
import numpy as np
from matplotlib import pyplot as plt
from mpl_toolkits.axes_grid1 import make_axes_locatable
import xscen as xs
output_folder = Path().absolute() / "_data"
# Create a project Catalog
project = {
"title": "example-diagnostics",
"description": "This is an example catalog for xscen's documentation.",
}
pcat = xs.ProjectCatalog(
str(output_folder / "example-diagnostics.json"),
create=True,
project=project,
overwrite=True,
)
Successfully wrote ESM catalog json file to: file:///home/docs/checkouts/readthedocs.org/user_builds/xscen/checkouts/latest/docs/notebooks/_data/example-diagnostics.json
3. Diagnostics
It can be useful to perform a various diagnostic tests in order to check that the data that was produced is as expected. Diagnostics can also help us assess bias adjustment methods.
Make sure you run GettingStarted.ipynb before this one, the GettingStarted outputs will be used a inputs in this notebook.
[3]:
# Load catalog from the GettingStarted notebook
gettingStarted_cat = xs.ProjectCatalog(
str(output_folder / "example-gettingstarted.json")
)
3.1. Health checks
NOTE
For more information on the available cfchecks, missing, and data_flags methods, please consult the xclim documentation.
Health checks located under xscen.diagnostics.health_checks are a series of checkups that can be performed on a Dataset to make sure that it has the expected structure, frequency, calendar, etc., with the ability to call xclim.core.cfchecks, xclim.core.missing, and xclim.core.dataflags. The function gives full control on which checkups should raise an Exception and which should only give a UserWarning.
The arguments are:
structure: Dictionary with keys “dims” and “coords” containing the expected dimensions and coordinates.calendar: Expected calendar. Synonyms should be detected correctly (e.g. “standard” and “gregorian”).start_date&end_date: To check if the dataset contains those.variables_and_units: Dictionary containing the expected variables and units.cfchecks: Dictionary ofxclim.core.cfchecksto perform, per variable.freq: Expected frequency, written as the result of xr.infer_freq(ds.time).missing: String, list of strings, or dictionary ofxclim.core.missingchecks to perform.flags: Dictionary ofxclim.core.dataflags.data_flagsto perform, per variable.
Additionally, flags_kwargs is used to pass additional arguments to the data_flags (“dims” and “freq”), while return_flags can be used to return the Dataset created by xclim.core.dataflags.data_flags;
Use the argument raise_on to list to list which test should raise an error if it fails. Use [“all”] to raise on all checks.
[4]:
# load input
# 'CMIP6_ScenarioMIP_NCC_NorESM2-MM_ssp245_r2i1p1f1_example-region' will be used for this example
ds = gettingStarted_cat.search(
id="CMIP6_ScenarioMIP_NCC_NorESM2-MM_ssp245_r2i1p1f1_example-region",
processing_level="regridded",
).to_dataset()
[5]:
# The checks that we want to perform. Note that all checks are optional.
structure = {"coords": ["lat", "lon", "time"]}
calendar = "365_day" # We have a standard calendar, so we'll be warned.
start_date = "1971-01-01" # The dataset starts on 1981-01-01, so this should fail
end_date = "2045-01-01" # The dataset ends later, but we check that it contains at least 2045-01-01.
variables_and_units = {"tas": "degC"} # The dataset is in Kelvin, so we'll get warned.
cfchecks = {"tas": {"cfcheck_from_name": {}}}
freq = "MS" # We actually have daily data, so we should get a warning.
missing = {"missing_any": {"freq": "D"}}
flags = {"tas": {"temperature_extremely_low": {}}}
[6]:
xs.diagnostics.health_checks(
ds,
structure=structure,
calendar=calendar,
start_date=start_date,
end_date=end_date,
variables_and_units=variables_and_units,
cfchecks=cfchecks,
freq=freq,
missing=missing,
flags=flags,
)
/home/docs/checkouts/readthedocs.org/user_builds/xscen/conda/latest/lib/python3.13/site-packages/xscen/diagnostics.py:294: UserWarning: The following health checks failed:
- The calendar is not '365_day'. Received 'proleptic_gregorian'.
- The start date is not at least 1971-01-01 00:00:00. Received 1981-01-01 00:00:00.
- The variable 'tas' does not have the expected units 'degC'. Received 'K'.
- The frequency is not 'MS'. Received 'D'.
3.2. Properties and measures
This framework for the diagnostic tests was inspired by the VALUE project. Statistical Properties is the xclim term for ‘indices’ in the VALUE project.
The xscen.properties_and_measures function is a wrapper for xsbda.properties and xsbda.measures.
xsbda.propertiesare statistical properties of a climate dataset. They allow for a better understanding of the climate by collapsing the time dimension. A few examples: mean, variance, mean spell length, annual cycle, etc.xsbda.measuresassess the difference between two datasets of properties. A few examples: bias, ratio, circular bias, etc.
Let’s start by calculating the properties on the reference dataset. You have to provide the path to a YAML file properties describing the properties you want to compute. You can also specify a period to select and a unit conversion to apply before computing the properties.
This example will use a YAML file structured like this:
realm: generic
indicators:
quantile_98_tas:
base: xsdba.properties.quantile
cf_attrs:
long_name: 98th quantile of the mean temperature
input:
da: tas
parameters:
q: 0.98
group: time.season
maximum_length_of_warm_spell:
base: xsdba.properties.spell_length_distribution
cf_attrs:
long_name: Maximum spell length distribution when the mean temperature is larger or equal to the 90th quantile.
input:
da: tas
parameters:
method: quantile
op: '>='
thresh: 0.9
stat: max
mean-tas:
base: xsdba.properties.mean
cf_attrs:
long_name: Ratio of the mean temperature
input:
da: tas
measure: xsdba.measures.BIAS
[7]:
properties = "samples/properties.yml"
period = [1981, 2010]
change_units_arg = {"tas": "degC"}
The properties can be given an argument group (‘time’, ‘time.season’ or ‘time.month’). For ‘time’, the time collapsing will be performed over the whole period. For ‘time.season’/’time.month’, the time collapsing will be performed over each season/month. See quantile_98_tas as an example for season.
[8]:
# load input
dref = gettingStarted_cat.search(source="ERA5-Land").to_dataset()
# calculate properties and measures
prop_ref, _ = xs.properties_and_measures(
ds=dref,
properties=properties,
period=period,
change_units_arg=change_units_arg,
to_level_prop="diag-properties-ref",
)
# save and update catalog
filename = str(
output_folder
/ f"{prop_ref.attrs['cat:id']}.{prop_ref.attrs['cat:domain']}.{prop_ref.attrs['cat:processing_level']}.zarr"
)
xs.save_to_zarr(ds=prop_ref, filename=filename, mode="o")
pcat.update_from_ds(ds=prop_ref, path=filename, format="zarr")
prop_ref
[8]:
<xarray.Dataset> Size: 1kB
Dimensions: (lat: 5, lon: 4, season: 4)
Coordinates:
* lat (lat) float64 40B 45.27 45.82 ... 46.92 47.47
* lon (lon) float64 32B -74.88 -74.62 -74.38 -74.12
* season (season) <U3 48B 'DJF' 'JJA' 'MAM' 'SON'
Data variables:
quantile_98_tas (season, lat, lon) float64 640B dask.array<chunksize=(4, 3, 2), meta=np.ndarray>
maximum_length_of_warm_spell (lon, lat) float64 160B dask.array<chunksize=(2, 3), meta=np.ndarray>
mean-tas (lat, lon) float64 160B dask.array<chunksize=(3, 2), meta=np.ndarray>
Attributes: (12/21)
cat:_data_format_: zarr
cat:activity: None
cat:date_end: 2011-12-24 00:00:00
cat:date_start: 1981-01-01 00:00:00
cat:domain: finer-grid
cat:experiment: None
... ...
cat:xrfreq: fx
comment: This is a test file created for the xscen tutori...
history: [2026-07-06 21:07:40] bbox spatial subsetting wi...
intake_esm_dataset_key: ECMWF_ERA5-Land_finer-grid.finer-grid.extracted.D
intake_esm_vars: ('tas',)
version: v20191108To compute a measure as well as a property, add the dref_for_measure argument with the reference properties calculated above. This will mesure the difference between the reference properties and the scenario properties. A default measure is associated with each properties, but it is possible to define a new one in the YAML (see mean-tas for example where the default (bias) was changed for ratio.)
[9]:
# load input
dscen = gettingStarted_cat.search(
source="NorESM2-MM",
experiment="ssp245",
member="r1.*",
processing_level="biasadjusted",
).to_dataset()
# calculate properties and measures
prop_scen, meas_scen = xs.properties_and_measures(
ds=dscen,
properties=properties,
period=period,
dref_for_measure=prop_ref,
change_units_arg={"tas": "degC"},
to_level_prop="diag-properties-scen",
to_level_meas="diag-measures-scen",
)
display(prop_scen)
display(meas_scen)
# save and update catalog
for ds in [prop_scen, meas_scen]:
filename = str(
output_folder
/ f"{ds.attrs['cat:id']}.{ds.attrs['cat:domain']}.{ds.attrs['cat:processing_level']}.zarr"
)
xs.save_to_zarr(ds=ds, filename=filename, mode="o")
pcat.update_from_ds(ds=ds, path=filename, format="zarr")
<xarray.Dataset> Size: 1kB
Dimensions: (lat: 5, lon: 4, season: 4)
Coordinates:
* lat (lat) float64 40B 45.27 45.82 ... 46.92 47.47
* lon (lon) float64 32B -74.88 -74.62 -74.38 -74.12
* season (season) <U3 48B 'DJF' 'JJA' 'MAM' 'SON'
Data variables:
quantile_98_tas (season, lat, lon) float64 640B dask.array<chunksize=(4, 5, 4), meta=np.ndarray>
maximum_length_of_warm_spell (lon, lat) float64 160B dask.array<chunksize=(4, 5), meta=np.ndarray>
mean-tas (lat, lon) float64 160B dask.array<chunksize=(5, 4), meta=np.ndarray>
Attributes: (12/25)
cat:_data_format_: zarr
cat:activity: ScenarioMIP
cat:bias_adjust_institution: Ouranos
cat:bias_adjust_project: xscen-tutorial
cat:bias_adjust_reference: ERA5-Land
cat:date_end: 2050-12-31 00:00:00
... ...
comment: This is a test file created for the xscen t...
history: [2026-07-06 21:07:42] regridded with argume...
intake_esm_dataset_key: CMIP6_ScenarioMIP_NCC_NorESM2-MM_ssp245_r1i...
intake_esm_vars: ('tas',)
regrid_method: bilinear
version: v20191108<xarray.Dataset> Size: 1kB
Dimensions: (lat: 5, lon: 4, season: 4)
Coordinates:
* lat (lat) float64 40B 45.27 45.82 ... 46.92 47.47
* lon (lon) float64 32B -74.88 -74.62 -74.38 -74.12
* season (season) <U3 48B 'DJF' 'JJA' 'MAM' 'SON'
Data variables:
quantile_98_tas (season, lat, lon) float64 640B dask.array<chunksize=(4, 3, 2), meta=np.ndarray>
maximum_length_of_warm_spell (lon, lat) float64 160B dask.array<chunksize=(2, 3), meta=np.ndarray>
mean-tas (lat, lon) float64 160B dask.array<chunksize=(3, 2), meta=np.ndarray>
Attributes: (12/25)
cat:_data_format_: zarr
cat:activity: ScenarioMIP
cat:bias_adjust_institution: Ouranos
cat:bias_adjust_project: xscen-tutorial
cat:bias_adjust_reference: ERA5-Land
cat:date_end: 2050-12-31 00:00:00
... ...
comment: This is a test file created for the xscen t...
history: [2026-07-06 21:07:42] regridded with argume...
intake_esm_dataset_key: CMIP6_ScenarioMIP_NCC_NorESM2-MM_ssp245_r1i...
intake_esm_vars: ('tas',)
regrid_method: bilinear
version: v20191108[10]:
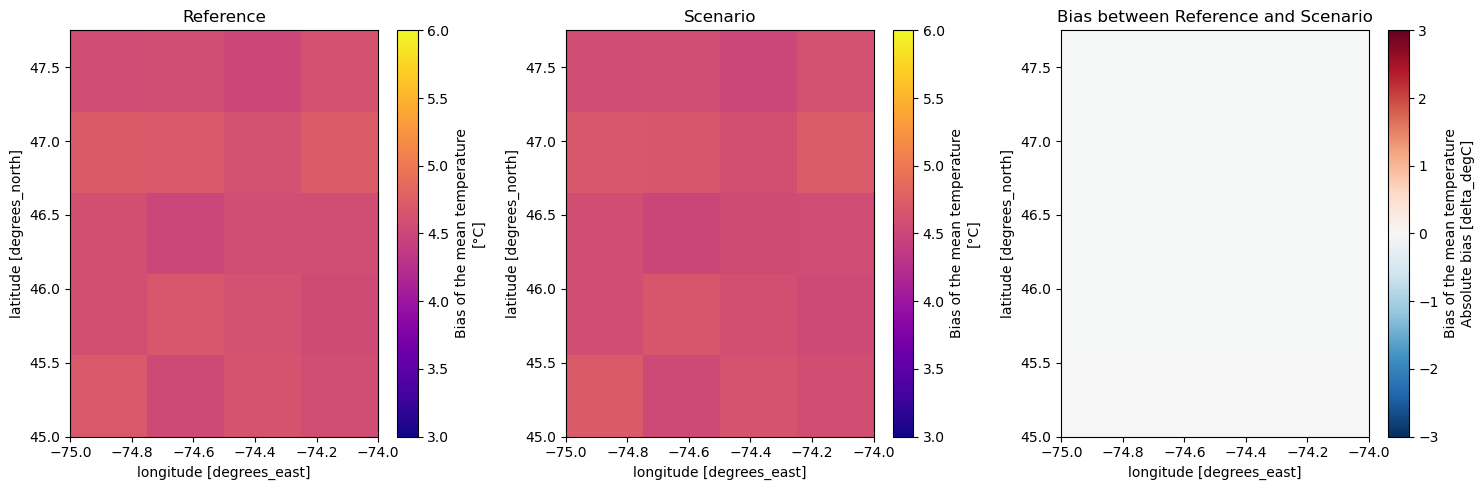
var = "mean-tas"
# plot
fig, axs = plt.subplots(1, 3, figsize=(15, 5))
prop_ref[var].transpose("lat", ...).plot(ax=axs[0], cmap="plasma", vmin=3, vmax=6)
prop_scen[var].transpose("lat", ...).plot(ax=axs[1], cmap="plasma", vmin=3, vmax=6)
meas_scen[var].transpose("lat", ...).plot(ax=axs[2], cmap="RdBu_r", vmin=-3, vmax=3)
axs[0].set_title("Reference")
axs[1].set_title("Scenario")
axs[2].set_title("Bias between Reference and Scenario")
fig.tight_layout()
If you have different methods of bias adjustment, you might want to compare them and see for each property which method performs best (bias close to 0, ratio close to 1) with a measures_heatmap.
Below is an example comparing properties of a simulation (no bias adjustment) and a scenario (with quantile mapping bias adjustment). Both the simulation and the scenario use the same reference for the measures.
Note that it is possible to add many rows to measures_heatmap.
NOTE
The bias correction performed in the Getting Started tutorial was adjusted for speed rather than performance, using only a few quantiles. The performance results below are thus quite poor, but that was expected.
[11]:
# repeat the step above for the simulation (no bias adjustment)
dsim = gettingStarted_cat.search(
source="NorESM2-MM",
experiment="ssp245",
member="r1.*",
processing_level="regridded",
).to_dataset()
prop_sim, meas_sim = xs.properties_and_measures(
ds=dsim,
properties=properties,
period=period,
dref_for_measure=prop_ref,
change_units_arg=change_units_arg,
to_level_prop="diag-properties-sim",
to_level_meas="diag-measures-sim",
)
# save and update catalog
for ds in [prop_sim, meas_sim]:
filename = str(
output_folder
/ f"{ds.attrs['cat:id']}.{ds.attrs['cat:domain']}.{ds.attrs['cat:processing_level']}.zarr"
)
xs.save_to_zarr(ds=ds, filename=filename, mode="o")
pcat.update_from_ds(ds=ds, path=filename, format="zarr")
[12]:
# load the measures for both kinds of data (sim and scen)
meas_datasets = pcat.search(
processing_level=["diag-measures-sim", "diag-measures-scen"]
).to_dataset_dict()
--> The keys in the returned dictionary of datasets are constructed as follows:
'id.domain.processing_level.xrfreq'
[13]:
from matplotlib import colors
# calculate the heatmap
hm = xs.diagnostics.measures_heatmap(meas_datasets=meas_datasets)
# plot the heat map
fig_hmap, ax = plt.subplots(figsize=(10, 2))
cmap = plt.cm.RdYlGn_r
norm = colors.BoundaryNorm(np.linspace(0, 1, 4), cmap.N)
im = ax.imshow(hm.heatmap.values, cmap=cmap, norm=norm)
ax.set_xticks(ticks=np.arange(3), labels=hm.properties.values, rotation=45, ha="right")
ax.set_yticks(ticks=np.arange(2), labels=hm.realization.values)
divider = make_axes_locatable(ax)
cax = divider.new_vertical(size="15%", pad=0.4)
fig_hmap.add_axes(cax)
cbar = fig_hmap.colorbar(im, cax=cax, ticks=[0, 1], orientation="horizontal")
cbar.ax.set_xticklabels(["best", "worst"])
plt.title("Normalised mean measure of properties")
fig_hmap.tight_layout()
/tmp/ipykernel_4749/1327646955.py:19: UserWarning: Tight layout not applied. The bottom and top margins cannot be made large enough to accommodate all Axes decorations.

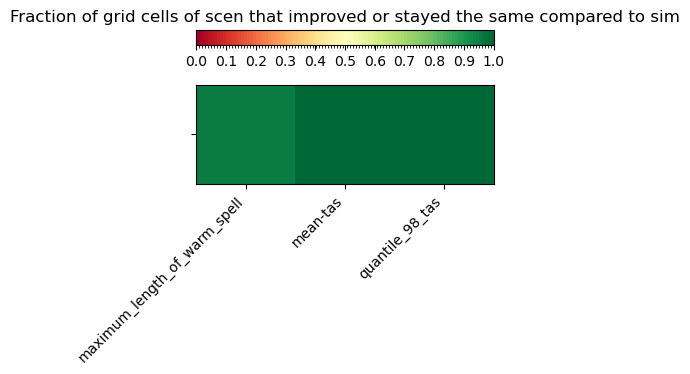
measure_improved is another way to compare two datasets. It returns the fraction of the grid points that performed better in the second dataset than in the first dataset. It is useful to see which of properties are best corrected for by the bias adjustment method.
[14]:
# change the order of meas_dataset to have sim first, because we want to see how scen improved compared to sim.
ordered_keys = [
"CMIP6_ScenarioMIP_NCC_NorESM2-MM_ssp245_r1i1p1f1_example-region.finer-grid.diag-measures-sim.fx",
"CMIP6_ScenarioMIP_NCC_NorESM2-MM_ssp245_r1i1p1f1_example-region.finer-grid.diag-measures-scen.fx",
]
meas_datasets = {k: meas_datasets[k] for k in ordered_keys}
pb = xs.diagnostics.measures_improvement(meas_datasets=meas_datasets)
# plot
percent_better = pb.improved_grid_points.values
percent_better = np.reshape(np.array(percent_better), (1, 3))
fig_per, ax = plt.subplots(figsize=(10, 2))
cmap = plt.cm.RdYlGn
norm = colors.BoundaryNorm(np.linspace(0, 1, 100), cmap.N)
im = ax.imshow(percent_better, cmap=cmap, norm=norm)
ax.set_xticks(ticks=np.arange(3), labels=pb.properties.values, rotation=45, ha="right")
ax.set_yticks(ticks=np.arange(1), labels=[""])
divider = make_axes_locatable(ax)
cax = divider.new_vertical(size="15%", pad=0.4)
fig_per.add_axes(cax)
cbar = fig_per.colorbar(
im, cax=cax, ticks=np.arange(0, 1.1, 0.1), orientation="horizontal"
)
plt.title(
"Fraction of grid cells of scen that improved or stayed the same compared to sim"
)
fig_per.tight_layout()
/tmp/ipykernel_4749/1692311341.py:29: UserWarning: Tight layout not applied. The bottom and top margins cannot be made large enough to accommodate all Axes decorations.